~ 12 min read
Coding Agents Do Not Replace Technical Proficiency — They Demand More of It

The pitch writes itself: describe what you want, let the agent produce the code, ship faster. And look, the productivity gains are real. I use coding agents daily across production codebases and I ship faster because of them. But after months of this workflow a pattern keeps showing up that the “AI replaces developers” crowd conveniently ignores. The developers extracting the most value from these tools already know what good code looks like. They know how their systems should be structured. They know which conventions their codebase follows and why. Technical proficiency is not what these tools replace. It is the prerequisite for using them well.
Without that grounding you are not steering anything. You are accepting whatever the agent gives you. And what it gives you, when it lacks your project context and your history of past mistakes, is often subtly wrong in ways that compound until someone has to untangle the mess six months later.
Table of contents
- LLMs are augmentation, not replacement
- How steering actually works
- The experience gap in agent interactions
- Speed versus correctness
- Where proficiency multiplies agent output
- How to know the agent got it right
- Security and performance
- Where this argument breaks down
- FAQ
LLMs are augmentation, not replacement
I keep coming back to this framing because it changes how you interact with the tool. When you feed more data and context to a model, its outputs improve. That is just how attention mechanisms and in-context learning work. But “providing context” is not a passive thing you do once. It requires knowing which context matters, which architectural decisions the model might accidentally violate, and where your abstractions have boundaries the model cannot see.
This plays out the same way across Cursor, Claude Code, GitHub Copilot, Windsurf, and every other agent I have used. The agent writes code faster than I can type. But it does not know my team migrated off a particular pattern three months ago. It does not know a given module uses dependency injection for testability reasons. It does not know a helper function already exists two directories over. That knowledge is my job. It has always been my job. The interface changed. The job did not.
And honestly this is not new. IDEs with autocomplete did not make understanding APIs optional. Static analysis did not make understanding type systems optional. CI pipelines did not make understanding deployment topology optional. Every tool in the history of software raised the floor for what a developer could accomplish in a given hour. None of them lowered the ceiling on what you needed to know to do the job well.
How steering actually works
I interact with coding agents differently now than I did when I first started using them. The difference is not prompt engineering tricks. It is knowing what to ask for, recognizing when the output is wrong, and having specific opinions about how things should be structured.
Here is a real example. I asked an agent to re-order output sections in a reporting module so that contributors appear right after the activity section. The agent explored the codebase, found the render function, moved the relevant lines.push(...) blocks, ran the test suite, confirmed it passed, and presented the diff.
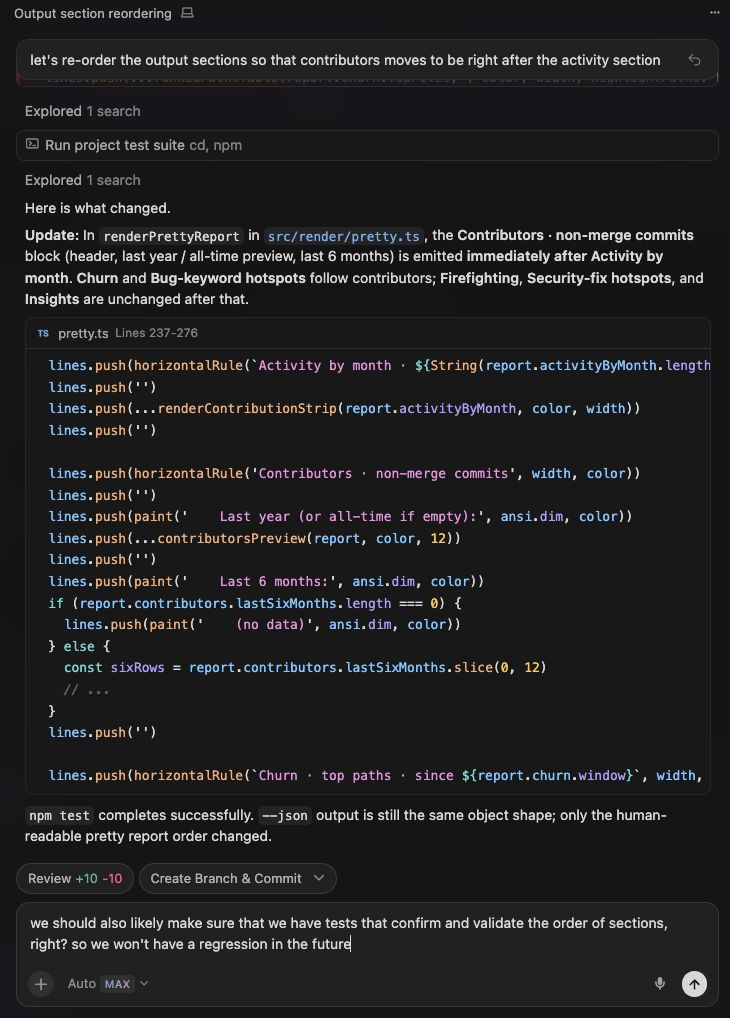
That interaction worked because I knew the intended reading order of the report. The agent did not invent that order. It moved code around based on my instruction. Without that specificity the agent either guesses (usually wrong) or asks clarifying questions you cannot answer without the same domain knowledge you would need to write the code yourself.
Same pattern when I pushed an agent toward the correct integration approach for database migrations. I was setting up integration tests with PGLite and needed migrations to run programmatically. The agent browsed the Drizzle ORM docs, found the migrate function from drizzle-orm/pglite/migrator, and proposed a clean implementation that reads migration files from a directory and applies them.
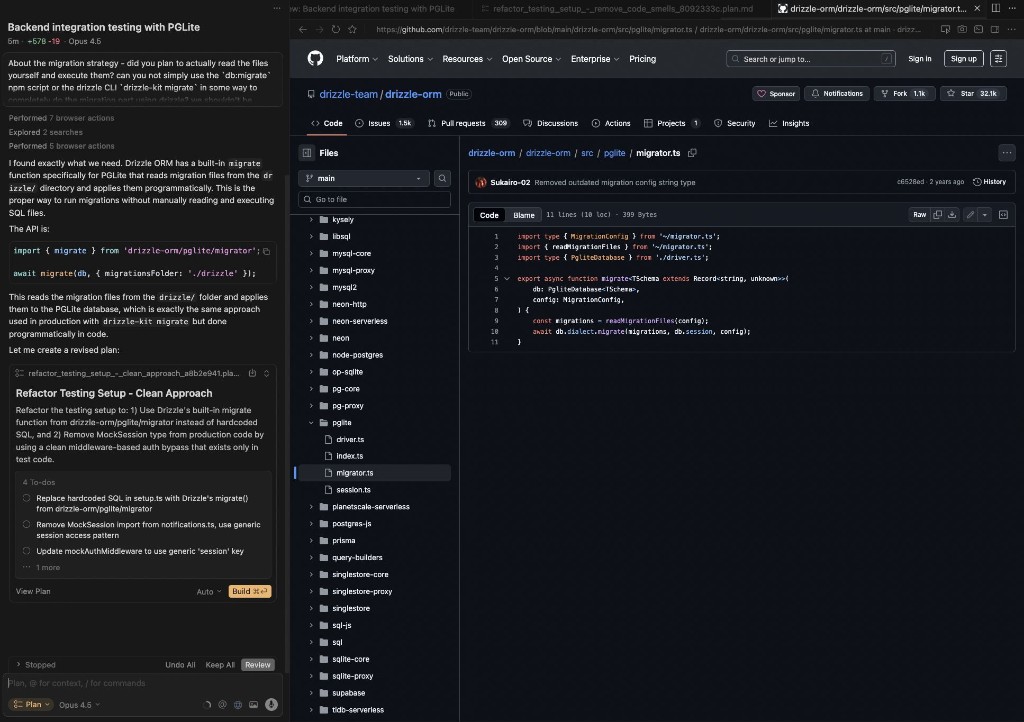
But that outcome only happened because I challenged the agent’s first suggestion. It initially wanted to hardcode SQL in the test setup file. I recognized that as a maintenance problem and pushed back: “Did you plan to actually read the migration files and execute them? You cannot simply use the db:migrate npm script or the drizzle-kit CLI in this way.” The agent corrected course. The correction came from me, not from the model.
This is what steering looks like. Not typing prompts into a box and hoping. It is an iterative conversation where my experience filters out bad suggestions, redirects toward patterns that match the project’s architecture, and validates that the end result is something I would have written myself, just faster.
The experience gap in agent interactions
When a developer lacks the background to evaluate what an agent produces, a few failure modes keep showing up:
- Convention drift. The agent writes code that works but does not follow established patterns. Over time the codebase collects inconsistencies that make future changes harder. No linter catches “we use the repository pattern here, not active record.”
- Outdated patterns baked in. The agent’s training data includes deprecated approaches and old API versions. If you do not know the current state of things, you will not notice when the agent is two years behind.
- Tests that exercise the wrong thing. The agent can generate test code. But a less experienced developer may not realize the generated tests only cover happy paths while skipping the edge cases that actually matter. If AI can write code, it can write test code too, but the question of what to test still requires judgment.
- Subtle architectural violations. The agent does not know that a module intentionally avoids a framework feature for performance reasons. It will happily re-introduce the abstraction you spent a sprint removing.
All of these produce code that passes CI, looks reasonable in a pull request, and slowly degrades the system. The cost is never immediate. It accumulates.
Speed versus correctness
Every team ends up somewhere on this spectrum and the right answer depends on what you are building.
| Approach | Speed | Correctness risk | When it fits |
|---|---|---|---|
| Accept agent output with minimal review | Very high | High: convention drift, subtle bugs | Throwaway prototypes, exploratory spikes |
| Agent writes, developer reviews each diff | High | Moderate: catches obvious issues, misses deep ones | Feature branches with experienced reviewers |
| Developer outlines architecture, agent fills in | Moderate-high | Low: the human defines the structure | Production systems with clear conventions |
| Developer writes critical paths, agent handles boilerplate | Moderate | Very low: creative work stays human-directed | Systems with safety or correctness requirements |
The right answer is not always the bottom row. Speed matters. Prototypes should ship fast. But for production systems that carry users and revenue, the job is not to go faster. It is to go correctly, and use the agent to reduce the tedious parts of getting there.
Where proficiency multiplies agent output
The amplification effect is clearest in a few categories of work.
Refactoring with intent. I know the target architecture. The agent has the patience to find every call site, update every import, run the tests, and chase down type errors across thirty files. My proficiency defines the destination. The agent handles the grunt work of getting there. Without that destination in mind you are refactoring toward… what?
Code review acceleration. I use agents to generate a first-pass review: style issues, potential null dereferences, missing error handling. But I still need to evaluate whether those suggestions are correct for my system’s contracts. A suggestion to “add null check here” is wrong if the type system guarantees non-null at that boundary.
Learning new territory. Agents are excellent at synthesizing documentation, showing API usage, and explaining unfamiliar libraries. But you need enough baseline knowledge to ask the right questions and know whether the answers are current. If you have never dealt with database migrations programmatically, you might accept the hardcoded SQL approach without knowing a proper migration runner exists two imports away.
Security auditing. Agents can scan for common vulnerability patterns: hardcoded secrets, SQL injection vectors, path traversal. But knowing whether a flagged pattern is actually exploitable in your deployment context requires the kind of threat modeling that comes from experience with production incidents and real security research.
How to know the agent got it right
Accepting agent output without verification is the failure mode this entire argument is about. Here is what I actually do:
Run the test suite after every agent-generated change. Obvious, but I have skipped it during rapid iteration and regretted it. If your tests pass, you have a baseline. If you have no tests, the agent just wrote unverified code into your production path.
Diff against your mental model. Before accepting a generated diff, ask yourself: “Is this how I would have structured it?” If yes, the agent saved you time. If no, figure out why. Maybe the agent found something better. Maybe it violated a constraint it does not know about.
Check for convention adherence. Does the generated code use the patterns established in neighboring modules? Does it import from the right locations? Does it follow naming conventions? Agents do not read your team’s style guide unless you explicitly feed it in as context.
Trace data flow manually. For anything touching authentication, authorization, or data persistence, trace the flow from entry to exit. Agents commonly miss edge cases in error handling, transaction boundaries, and cleanup paths.
Verify dependency choices. When an agent adds an import or a new package, check it against your dependency policy and lockfile. The agent may suggest a package you already excluded for security or licensing reasons.
Security and performance
Coding agents introduce a specific kind of security risk that inverts the traditional problem. Historically, vulnerabilities came from developers making mistakes. With agents, vulnerabilities come from developers accepting mistakes they did not make and therefore did not reason about.
An agent generating a database query might skip parameterized inputs if the surrounding code does not make the ORM’s query builder obvious. An agent setting up an auth flow might store tokens in localStorage because that is the most common pattern in its training data, even though your security requirements demand httpOnly cookies. An agent adding an API endpoint might skip rate limiting, input validation, or CORS headers unless you explicitly ask for them.
Performance follows the same shape. An agent will produce functionally correct code that may be wildly inefficient for your data scale. It does not know the table has 40 million rows. It does not know the API handles 10,000 requests per minute. It does not know the lambda has a 128MB memory limit. Writing code that performs well at scale requires context the agent does not have unless you provide it, and providing it requires knowing it matters in the first place.
The security posture of AI-assisted codebases is not worse automatically. It is worse when the humans in the loop cannot catch what the agent misses. That kind of catch comes from experience with threat modeling and production incidents. No amount of training data replicates it.
Where this argument breaks down
I want to be honest about the limits here. Agent capabilities are improving fast. Context windows are growing. Retrieval mechanisms are getting better at surfacing relevant project context. Some agents can read entire codebases before suggesting changes. The gap between what the agent knows and what the developer knows will narrow over time.
But it will not close to zero, and here is why. Engineering decisions are often implicit. They live in commit messages, Slack threads, incident postmortems, and the developer’s memory of why something was built a certain way. No amount of indexed code captures the full decision history. And correctness in software is domain-specific. An agent cannot know your financial system must never round intermediate calculations, or that your healthcare app must log every data access for compliance, unless someone wrote those constraints down somewhere the agent can read.
Future agent tooling will probably address some of these gaps with better project-level memory, intent-aware generation (understanding why a pattern exists, not just replicating it), and tighter feedback loops between validation tools and the generation step. But each of those advances makes experienced developers more productive. It does not make inexperienced developers equivalent. The ceiling goes up along with the floor.
The tools will keep getting better. The need to understand what you are building is not going anywhere.
FAQ
Does this mean junior developers cannot benefit from coding agents? They benefit enormously. Agents accelerate learning by showing how things can be done. But the learning itself still has to happen. Using an agent as a crutch without understanding the output is copy-pasting from Stack Overflow without reading the explanation. It works until it does not, and when it breaks you cannot debug what you never understood.
If I review every diff, am I actually saving time? Yes. Review is faster than generation. Writing fifty lines of boilerplate takes twenty minutes. Reviewing fifty lines to confirm they match your patterns takes three minutes. The savings are real, especially for repetitive structural work like migrations, test scaffolding, and endpoint plumbing.
How do I build the proficiency this post argues for? Same way it was always built. Write systems. Debug production incidents. Read other people’s code. Contribute to open source. Work across different layers of the stack. Agents can speed this up (ask them to explain unfamiliar code, generate exercises, propose alternatives), but the experience itself cannot be skipped.
Will future agents make this argument obsolete? Maybe eventually, but not soon. The structural gaps (implicit project knowledge, domain-specific correctness, evolving team conventions) are not problems you solve by making models bigger. They require architectural changes in how agents integrate with development workflows: persistent memory, intent modeling, convention enforcement at generation time. Those are research areas, not shipped products.
What is the difference between context-stuffing and genuine steering? Context-stuffing is dumping documents on the agent and hoping it figures out what matters. Steering is knowing which constraint applies to this specific change and saying so directly: “use the repository pattern, not direct DB queries” or “this module avoids framework X for latency reasons.” One is passive. The other is active engineering judgment delivered through a new interface.
The tools are good. Use them. But use them as someone who knows what they are building, not as someone hoping the model will figure it out. Follow @liran_tal on X for more on developer tooling, security, and engineering practice. Explore code and projects at github.com/lirantal.
